We Invented a Dental Clinic to Test Whether Knowledge Bases Actually Fix Voice AI
Every agency selling voice AI hears the same question: will a knowledge base actually change what the agent says, or is it just another checkbox?
Fair question. Modern LLMs already sound articulate. They answer in complete sentences. They rarely pause or hedge. On a phone call, that confidence is exactly what makes a wrong answer dangerous.
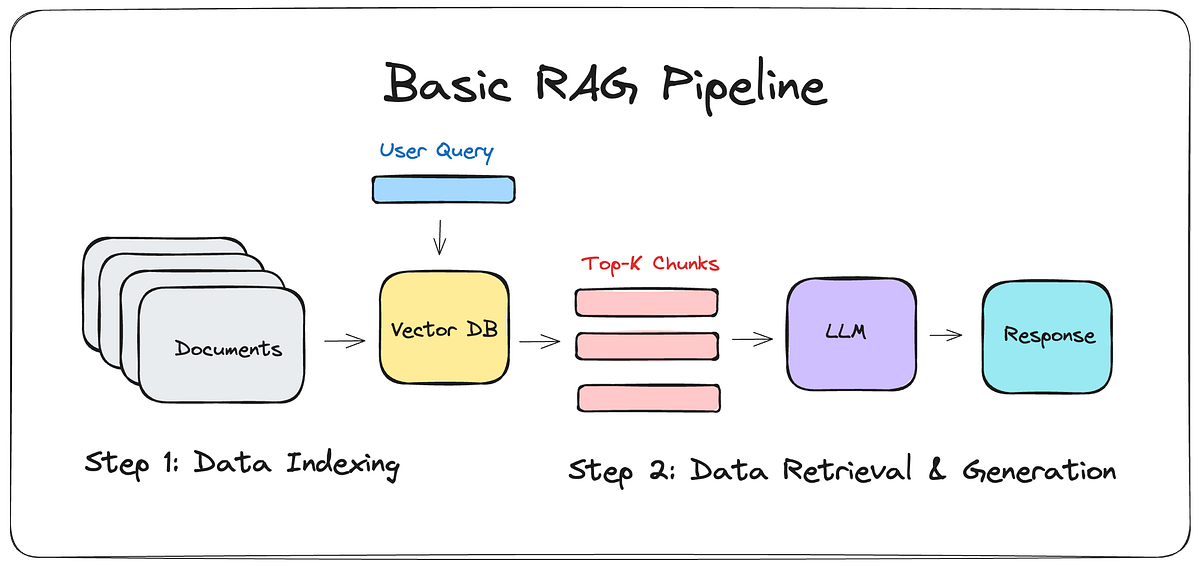
So we ran a controlled A/B test. Same agent, same 12 caller questions, same voice model. The only variable: whether we retrieved chunks from a company document into the prompt before the agent answered.
To keep it clean, we invented the company.
| Metric | Result |
|---|---|
| Correct without knowledge base | 5 / 12 (42%) |
| Correct with knowledge base | 12 / 12 (100%) |
| Hallucinations with knowledge base | 0 (4 without) |
| Retrieval overhead | ~45 ms per answer |
The question everyone asks
Clients upload a PDF with their prices, hours, and policies. They attach it to their agent. Then they call the line and ask something specific: how much is a checkup? or do you take Amex?
Does the document change the answer, or does the model just wing it?
We wanted a reproducible answer, not a sales pitch. So we built a test harness, wrote a one-page fact sheet for a fictional clinic, and graded every response with an independent LLM judge.
What we actually did
Meet Harborview Dental Care, a made-up family dental clinic in Western Australia. We wrote a single-page fact sheet covering hours, fees, cancellation policy, payment methods, parking, walk-in rules, and languages spoken at reception. Every fact in the sheet is deliberate. Some of them contradict what a model would normally guess.
That last part matters. We did not only ask questions the model could never know (like a $129 new-patient special). We also wrote trap questions: questions where the model's most likely default answer is plausible, confident, and wrong.
Trap facts we baked into the document on purpose:
- Cancellation requires 48 hours notice, not the usual 24.
- They do not accept walk-ins for routine appointments.
- They do not take American Express.
We ran 12 questions through the same Cerebras-hosted agent. For each question, we called it twice: once with no knowledge base, once with the top four matching chunks retrieved from the fact sheet. An independent LLM judge scored each answer against the source document: correct, incorrect, or declined, plus a hallucination flag.
| Type | Count | What it tests |
|---|---|---|
| Proprietary | 6 | Only answerable from the document: prices, hours, parking. |
| Trap | 3 | Document contradicts the model's likely guess: cancellation, walk-ins, Amex. |
| General | 3 | Ordinary dental advice the model already knows. A control group. |
The numbers
| Metric | No knowledge base | With knowledge base |
|---|---|---|
| Correct answers | 5 / 12 (42%) | 12 / 12 (100%) |
| Hallucinations | 4 | 0 |
| Average judge score (0-5) | 2.67 | 5.0 |
| Retrieval overhead | n/a | ~45 ms |
| Category | No KB | With KB |
|---|---|---|
| Proprietary | 2 / 6 | 6 / 6 |
| Trap | 0 / 3 | 3 / 3 |
| General | 3 / 3 | 3 / 3 |
The knowledge base did not make the agent smarter in general. It made it accurate on your facts. That distinction is the whole point.
Trap questions: where confidence becomes a liability
This is the part that should worry anyone running a no-knowledge-base agent on a live phone line. The agent without a document did not hesitate. It did not say "I'm not sure." It gave clear, polite, wrong answers.
| Caller question | Without knowledge base | With knowledge base |
|---|---|---|
| "If I need to cancel, how much notice do you need?" | "At least 24 hours' notice... may be subject to a small fee." | "At least 48 hours' notice. Less than 48 hours or no-shows incur a $75 fee." |
| "Can I just walk in for an appointment today?" | "We do accept walk-ins... call us at (555) 123-4567." Invented a phone number. | "We don't accept general walk-ins. Dental emergencies: call before 11am for a same-day slot." |
| "Do you take American Express?" | "Yes, we accept American Express, along with Visa, MasterCard and Discover." | "We accept cash, EFTPOS, Visa and Mastercard, but we don't take American Express." |
A confidently wrong cancellation policy is worse than no answer. It creates disputes, missed appointments, and chargebacks. A made-up phone number sends callers somewhere that does not exist. These are not edge cases. They are the default behavior when you ask a general-purpose model to speak for a specific business.
Facts the model simply cannot know
On proprietary questions, the no-KB agent guessed ranges that sounded reasonable:
| Caller asks | Without KB | With KB |
|---|---|---|
| New-patient checkup and clean | "around $150-$180" | $129 |
| In-chair teeth whitening | "$350-$550" | $590 |
| Open on Saturdays? | "closed on Saturdays" | 1st and 3rd Sat, 9am-1pm |
None of these are exotic questions. They are the first things a real caller asks. Without a knowledge base, the agent fills the gap with plausible fiction.
Where the knowledge base changed nothing (on purpose)
On the three general questions ("how often should I get a checkup?", "is flossing necessary?", "what helps sensitive teeth?"), both agents scored 3/3. The knowledge base added nothing there because the answers do not depend on Harborview's private information.
That is what makes this a trustworthy result rather than marketing fluff. A knowledge base is targeted grounding for company-specific facts. It changes the answers that should change and leaves the rest alone. You are not buying general intelligence. You are buying accuracy on your prices, policies, and procedures.
The prompt mistake we almost shipped
Our first attempt told the agent to "only answer from the knowledge base." Hallucinations dropped, but the agent started refusing ordinary questions it could easily handle. General accuracy fell to 0/3. Useless on a real call.
The fix was one instruction change: use the knowledge base as the source of truth for company-specific facts, but still answer general questions normally. That took the with-KB agent to a clean 12/12.
The knowledge base is necessary but not sufficient. The prompt that frames it matters just as much. We bake this into our production agent templates now.
What this means for your phone line
If your agent answers questions about your prices, hours, policies, or services, a knowledge base is not a nice-to-have. It is the difference between an agent that confidently misinforms callers and one that gets it right.
If your agent only gives generic advice and never touches business-specific facts, you probably do not need one.
The setup is straightforward: upload a fact sheet, FAQ, or price list in the dashboard, attach it to the agent, and add a short prompt block that tells the model to ground company facts in the document without over-restricting general questions. Retrieval adds about 45 ms. On a phone call, behind a brief acknowledgement, that is invisible.
Before we ship a knowledge-base agent for a client, we run the same style of test against their documents: a dozen real caller questions, including a few traps where the model's default guess sounds right but is wrong. Those traps are what tell you whether the knowledge base is actually working.
Want to see this on a live PBX extension? Request a demo and we will walk you through attaching a knowledge base to an agent on your line.